Your AI Just Leaked a Secret
I found verified, live credentials leaking from Microsoft, Google, Red Hat, Grafana, and LlamaIndex in public GitHub repositories. Not stale junk; tokens that, at the moment of discovery, still authenticated against their issuing API. Microsoft Research’s microsoft/maro repo shipped a working Weights & Biases token from a @microsoft.com account. A Google employee leaked a WandB token that exposed ten internal Google projects, including an unreleased model called gemma_nemo_sft. Another Google account leaked a Cloudflare token with zone admin permissions on production infrastructure. Red Hat, Grafana, LlamaIndex, BerriAI, Intel: same pattern, different repo.
I built the pipeline that found them. It watches the GitHub Archive firehose for commit messages that smell like a developer just leaked a credential, fetches the diff, and runs TruffleHog with verification on. Over a few months it surfaced 3,830+ verified live secrets across 1,443 unique repositories. After direct outreach, 95%+ rotated within two weeks.
The reason this number keeps climbing has a name and you can guess it. Developers ship faster with AI in the editor, security review shrinks, and the secret that lives in line 42 of a Cursor-generated config.py lands in a public commit before anyone reads the diff. Your AI just leaked a secret. More precisely: it helped you ship one to GitHub, where attackers index credentials in single-digit minutes.
The shape of the problem
GH Archive ships a JSON event stream for every public action on GitHub: pushes, PRs, issues, stars. The only events that matter for leaked secrets are PushEvent (commit messages + SHAs) and PullRequestEvent (PR titles, but only on opened / reopened). Everything else is exhaust.
A normal hour of PushEvent is roughly 250k commits. The signal I want is a tiny subset of those:
remove api key
revoke aws credentials
delete .env
rotate token, pushed by mistake
fix: leaked secret
Naive grep on key|token|secret|password catches the signal and drowns in matches like “keyboard shortcut”, “session token refresh”, “password input component”. The detection rate is fine. The false positive rate is unworkable when the next step is cloning the repo, fetching the diff, and running a binary on it.
The first naive run on a single GH Archive hour file blew through my Gemini free-tier quota in under a minute and still had hours of commits left to label. AI-first does not scale. Grep-first matches too much. Both lose.
Phase 1: just ask the LLM
The first version was the lazy one. Every commit message went straight into Gemini 2.5 Flash Lite with a one-shot prompt:
prompt = f"""
Analyze the following Git commit message to determine if it is fixing a secret leak.
The message might mention revoking, removing, or rotating keys, tokens, passwords, or other credentials.
Respond with only "true" if it is highly likely to be fixing a secret leak, otherwise respond with "false".
Commit Message:
---
{commit_message}
---
"""
This works. Flash Lite is good at this task and the response is one token. But pumping every PushEvent message through an API call is expensive and slow even on a cheap tier, and rate limits hit fast.
So I batched it. 250 commits per request, JSON-formatted reply, indexed by position:
BASE_PROMPT_TEMPLATE = """
Analyze the following Git commit messages to determine if any of them are fixing a secret leak.
A message is considered to be fixing a secret leak if it mentions revoking, removing, or rotating keys, tokens, passwords, or credentials.
Return a JSON object where each key is the numeric index of the commit message (as a string) and the value is a boolean (`true` or `false`).
Ensure your response is only the JSON object.
"""
The batch path was faster and cheaper but still bottlenecked on AI calls. After a few weeks of running, two log files had grown enormous:
suspicious_commit_messages.log 59,014 lines
not_suspicious_commits.log 793,199 lines
That is roughly 852,000 messages labeled by Gemini. The cache made repeated AI calls free, but new traffic kept costing. The bigger lesson sitting in those two files was: the labels were not random. They clustered.
Phase 2: stealing the regex from the model
If you sort suspicious_commit_messages.log and skim it, the structure jumps out. Almost every true-positive is a verb plus a noun. The verbs are tiny:
remove, delete, revoke, invalidate, rotate, regenerate, leak, expose, compromise, fix
The nouns are larger but bounded. A few generic words (key, token, secret, credential, password), and then a long tail of brand-specific names: aws, openai, slack, stripe, datadog, mongodb_uri, firebase, on and on. Every cloud, every SaaS, every CI provider, every payment processor.
So I asked the model to do something different. Not “classify this message”, but “give me the patterns you are using to classify it”. The output became a small grammar.
I split it into two tiers. The high-confidence tier is verbs + nouns that are almost always about secrets:
HIGH_CONFIDENCE_ACTION_VERBS = [
"remove", "delete", "revoke", "invalidate",
"rotate", "regenerate", "leak", "expose",
"compromise", "fix",
]
HIGH_CONFIDENCE_OBJECT_NOUNS = [
"api_key", "apikey", "access_token", "auth_token",
"private_key", "secret_key", "client_secret",
"credential", "credentials", "password", "passwd",
"aws_secret", "aws_access_key", ".env", "dotenv",
# ...
]
The broad tier is forgiving verbs like update and change, plus the long tail of brand names. Hundreds of detector keywords pulled directly from TruffleHog’s own detector catalog (stripe, twilio, mailgun, sendgrid, slackbot, cloudflare, algolia, and so on) plus generic infra terms.
BROAD_ACTION_VERBS = [
"update", "change", "fix", "patch", "clean",
"remove", "delete", "purge", "wipe", "scrub",
# ...
]
On top of that, three compiled regexes catch the canonical “I just leaked a secret” message shapes directly:
SECRET_REMOVAL_PATTERNS = [
re.compile(r'\b(remove|delete|revoke|invalidate|rotate|regenerate)\b.*\b(key|token|secret|password|credential)\b', re.IGNORECASE),
re.compile(r'\b(fix|patch)\b.*\b(leak|expose|compromise)\b', re.IGNORECASE),
re.compile(r'\b(revert)\b.*for.*security.*reason', re.IGNORECASE),
]
The first one alone catches a huge chunk of the truly self-incriminating commits. People literally write Remove leaked API key in their commit message, every single day, in public.
Phase 3: regex first, model only when stuck
With the grammar in hand, the pipeline flipped. The default path is now:
- Apply
SECRET_REMOVAL_PATTERNS. If any hit, flag the commit. - Apply tier 1 (high-confidence verb AND high-confidence noun in the same message). If hit, flag.
- Apply tier 2 (broad verb AND broad noun). If hit, flag.
- Only if a message is ambiguous and not in either cache, fall back to Gemini.
This is regex-first, AI-fallback. The AI is no longer in the hot path. It became a tiebreaker for the long tail.
Two side benefits I did not plan for:
- The pipeline became deterministic and replayable. Same input, same output, no API drift between runs.
- The pipeline became cheap to run offline. No quota, no rate limits, no network. The only network I/O is fetching the diffs and running TruffleHog.
Anything the regex misses still gets sent to Gemini, and any new true positive Gemini finds becomes a candidate for the next regex update. The model is now training the filter, not running it.
Phase 4: active verification, not just detection
A pattern match on a key shape is noise. A working API call is a finding. Every TruffleHog detector ships with a verifier function: take the candidate string, build the issuing service’s authentication request, observe the response. AWS access keys hit sts:GetCallerIdentity. GitHub PATs hit /user. Postgres URIs open a TCP connection and SELECT 1. WandB tokens hit /graphql and resolve the user identity.
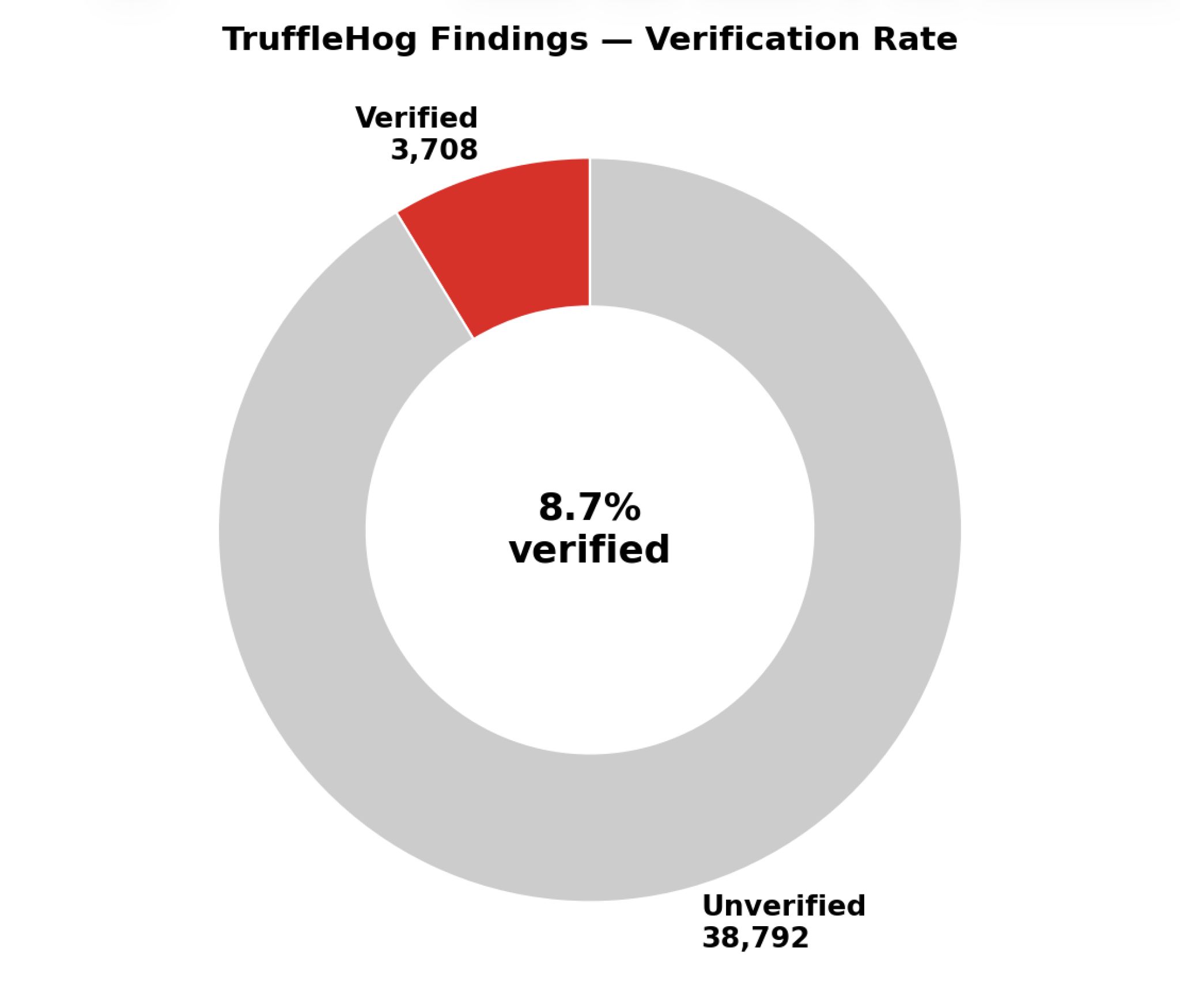
Verification is what kills the false positive problem and what turns “interesting looking string” into “credentialed access right now”. In my dataset, of roughly 42,500 candidate strings the filter sent to TruffleHog, 3,708 returned verified (an 8.7% verify rate). Everything else was test fixtures, expired tokens, scrambled examples, or non-credential strings that happened to match a key shape.
Verification also unlocks the next step: enumeration. A verified WandB token does not just say “this is real”, it lets you walk the GraphQL schema and list the user’s projects, runs, and team members. That was how the Microsoft and Google cases below went from “leak” to “blast radius mapped” in minutes.
Notable victims
A small selection from the dataset. Every one of these was reported, verified by the org, and rotated. The leaks were not malicious. They were velocity.
Microsoft Research, MARO repo, Weights & Biases token
microsoft/maro is a Microsoft Research multi-agent reinforcement learning library, 885 stars. A @microsoft.com employee committed a working W&B API token. The token authenticated. The W&B GraphQL endpoint returned the user object: full name, corporate email, team affiliation, and the list of training runs the account had access to. Reported through Microsoft’s VRP, rotated within 3 days.
![The remediation diff in microsoft/maro: `os.environ["WANDB_API_KEY"] = "116a4f287fd4fbaa6f790a50d2dd7f97ceae4a03"` and `wandb.login()` removed from examples/rl/main.py](/assets/images/hunting-leaked-secrets/microsoft-maro-wandb-diff.jpg)
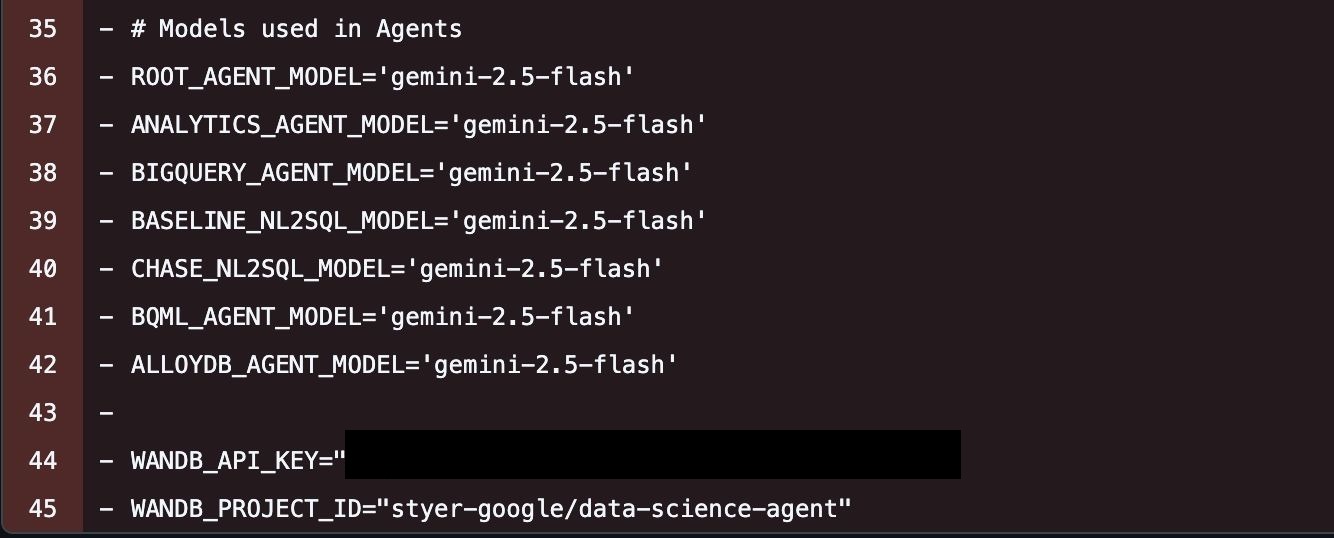
Google employee, Weights & Biases token, ten internal projects
A @google.com employee leaked a WandB token. Authenticating with it revealed ten internal Google ML projects, including model training infrastructure that had not been publicly announced. One of the project names by itself was the finding: an unreleased model called gemma_nemo_sft. Others included multimodal-function-calling, pytorch-sweeps, data-science-agent. Reported, rotated within 7 days.
Google account, Cloudflare token, zone admin
Different @google.com account, different leak: a Cloudflare API token with zone admin permissions on production DNS infrastructure. With that token the attack chain is short and ugly: modify DNS records, redirect traffic, MITM at the edge. Reported through Google’s VRP, rotated within 48 hours.
The rest of the wall
grafana/grafana (69,202 stars) shipped a working AWS access key. run-llama/llama_index (43,358 stars) and BerriAI/litellm (26,438 stars), both core infrastructure in the AI/LLM ecosystem, each leaked their own service tokens. intel/BigDL (2,680 stars), Red Hat repositories, multiple LlamaIndex sub-projects. Every name in this list is a place a competent security team works. The leaks still happened.
What TruffleHog found, in aggregate
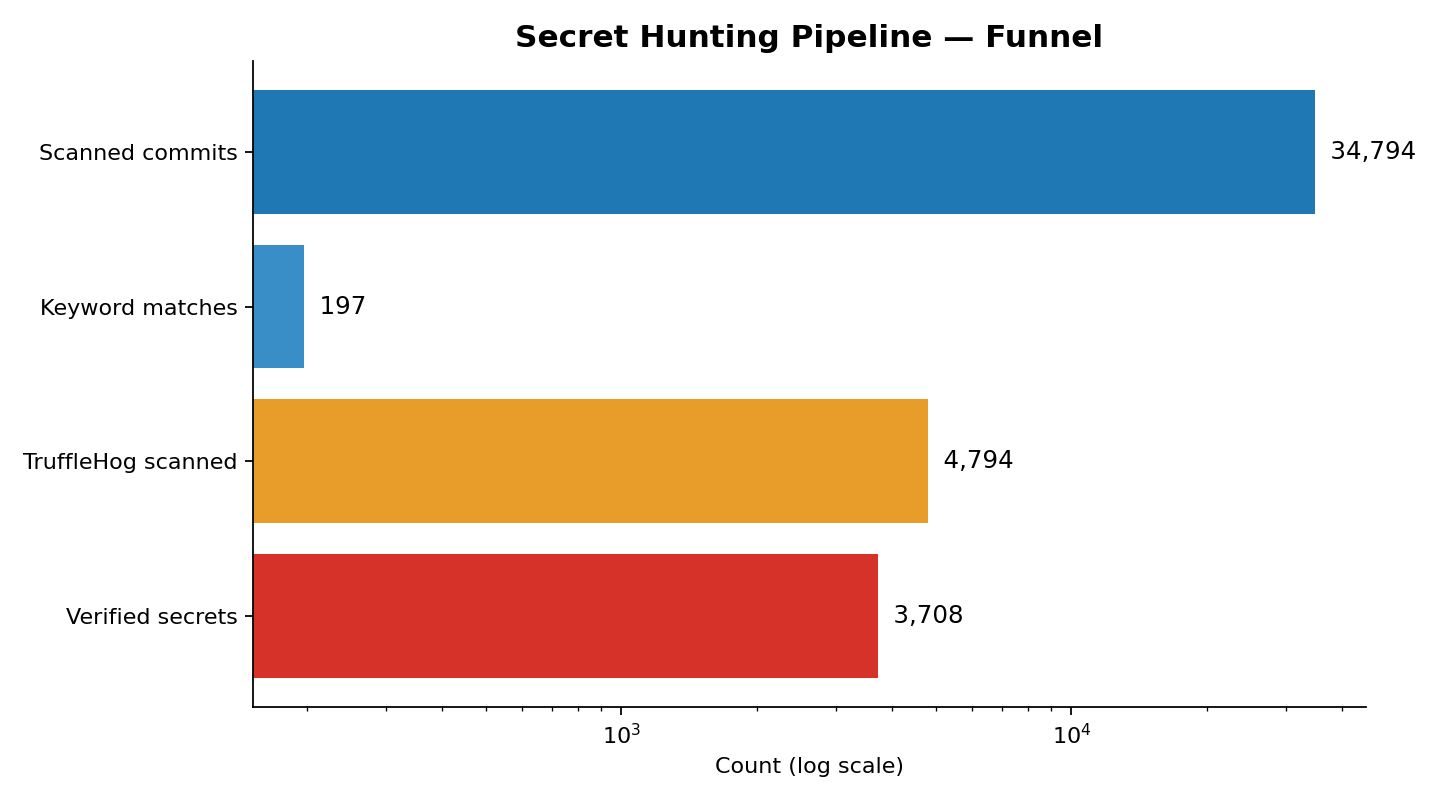
Once a commit message passed the filter, the pipeline fetched the diff from GitHub and ran TruffleHog with verification enabled. Final numbers from one batch run:
PushEvent commits scanned (after filter) 34,794
Unique commit messages matched (keyword) 197
Verified secret records 3,708
Unique commits containing a verified secret 1,702
One matched message frequently maps to hundreds of commits: thousands of different developers literally commit remove api key verbatim, and every one of those commits gets pulled. So 197 unique messages expanded into 34,794 commits to scan.
The detector distribution is the actually useful chart. Database credentials dominate (Postgres, MongoDB, blockchain RPC URIs), followed by Telegram bot tokens, HuggingFace tokens, Vercel deploy tokens, and the long tail of AI infrastructure: DeepSeek, Groq, Weights & Biases, ElevenLabs.
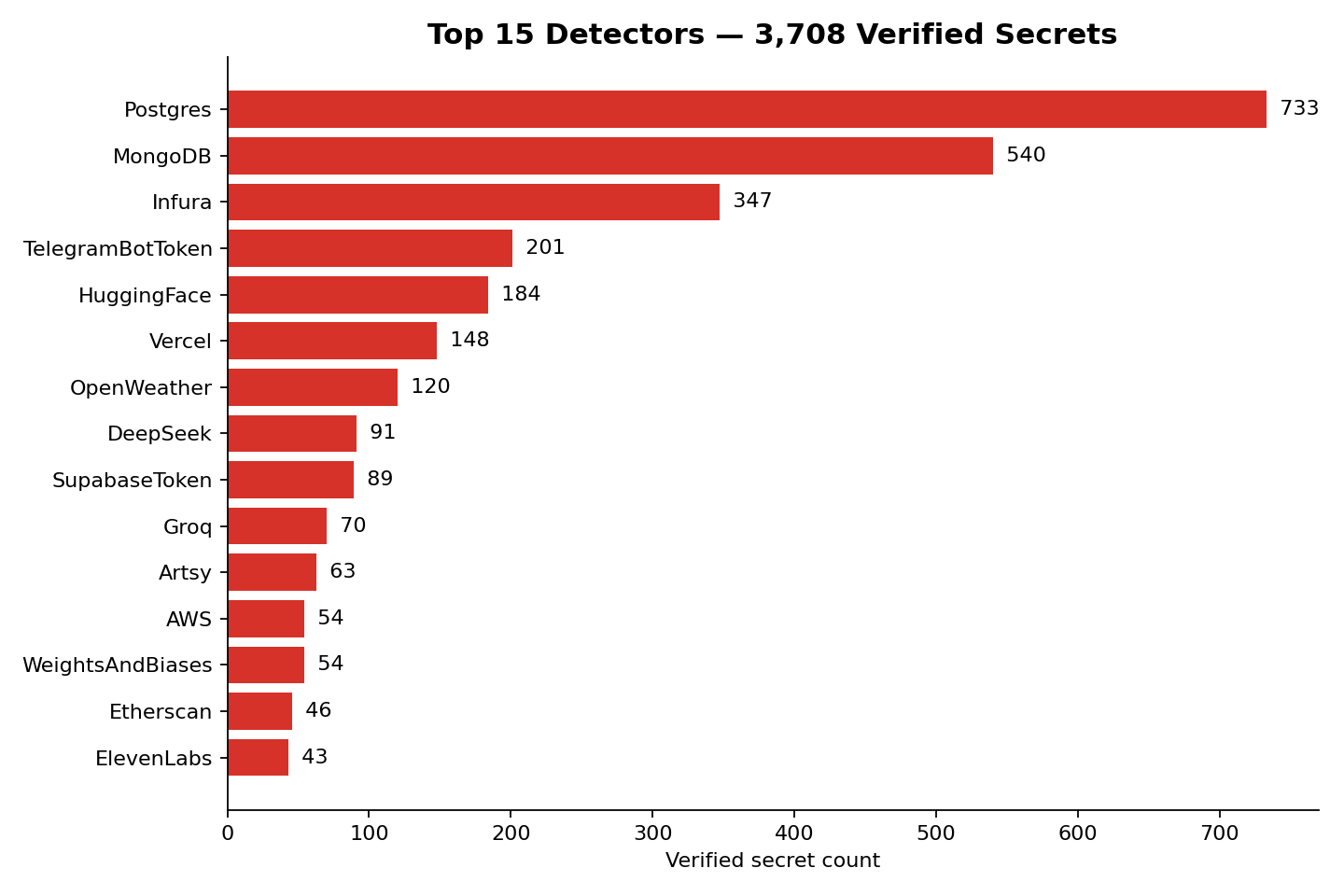
If you want a sense of how fast “leak on GitHub” becomes “exploit”, Mackenzie Jackson and Andrzej Dyjak ran the canary experiment back in 2020: an AWS key seeded via canarytokens.org, pushed to a public repo, was first abused 11 minutes after the push (What actually happens when you leak credentials on GitHub). My pipeline runs on a 5 to 15 minute lag against GH Archive. The attackers are not slower than me, and they are no longer the ones doing the typing.

The AI angle: why this keeps getting worse
Two facts together:
-
AI assistants write code faster than humans can review it. The compounding effect is: more lines produced per developer per day, the same number of eyes per line on the way to
git commit. The probability that a hardcoded key in generated boilerplate gets caught at review time goes down, monotonically, as autocomplete acceptance rates go up. -
LLMs were trained on GitHub. The patterns the model autocompletes were lifted from the patterns that already shipped, including the ones that leaked. Ask an assistant to “write me a quick script to upload to S3” and there is a non-trivial chance it scaffolds a literal
AWS_ACCESS_KEY_ID = "..."line as a placeholder, with the comment# replace with your key. Sometimes the developer replaces it. Sometimes they paste the real key in, hit save, and commit.

The defenders use AI too. TruffleHog detectors now use context-aware classifiers to reduce false positives on key shapes that historically tripped regex. LLM scanners beat plain regex on near-miss obfuscations. Both sides shipped AI into the same loop, and the side with the worse defaults loses first.
Remediation: rotate, then clean
Once a key has shipped, every minute you spend on the file before the issuer is a minute the attacker still has the credential. Rotate first at the issuer, not in the file. Revoke the old credential and mint a new one before touching anything else. Then read the access log for the leaked key end to end, look for IPs and user agents you do not recognize, and assume the attacker arrived before your alert did.
Only after the credential is dead, clean up git history. A plain git rm and a new commit just hides the key behind a SHA; the original is still reachable and forks and clones picked it up within minutes. The correct fix is a full history rewrite with git-filter-repo:
# Remove the file from every commit
git-filter-repo --sensitive-data-removal --invert-paths --path config/secrets.yml
# Or replace specific values across history
echo 'sk-deadbeef0123456789' >> ../passwords.txt
git-filter-repo --sensitive-data-removal --replace-text ../passwords.txt
Force-push, then ask GitHub Support to purge cached commit URLs, diff views, and PR caches. Otherwise the credential is still searchable through the API for hours.
For the “what runbook do I follow per provider” question, howtorotate.com/docs/tutorials keeps a step by step rotation guide for AWS, GCP, GitHub PATs, Stripe, Postgres, and most of the issuers in my dataset. As of 2026-06 it is the most actively maintained per-provider runbook set I have found.
Rotation: stop relying on humans to remember
Manual rotation works for ten secrets and falls over at a thousand. The teams that survive their first leak converge on the same three habits:
- Short-lived tokens by default: OIDC federation for CI (GitHub Actions
id-token: write, AWSAssumeRoleWithWebIdentity), workload identity for cloud workloads, 15 minute to 1 hour TTLs for human access. A 15 minute token is a non-event by the time it is indexed. - Credential-free architecture where possible: IAM roles instead of access keys, service accounts instead of static tokens, mTLS between services. The credential that does not exist cannot leak.
- A secrets manager and a 90 day rotation cycle for everything long-lived that is left: Vault, AWS Secrets Manager, Doppler, GCP Secret Manager. The choice matters less than ending the era of
.envfiles in repos. The cadence is the load-bearing control.
And the defense layers that catch what slips through: pre-commit (TruffleHog, gitleaks, git-secrets) blocks at the developer laptop; the same scanners in CI catch the --no-verify bypass; nightly full-history scans catch legacy keys that predate the hooks; GitHub Secret Scanning runs across every public repo against ~130 partner patterns and often auto-revokes a real key before you finish writing the rotation message. For AI editors, Wiz Secure Rules teaches Cursor, Copilot, Cline, and Windsurf to refuse hardcoded credentials at generation time, which is the closest thing to fixing CWE-798 at the source.
What this implies if you ship code
Commit messages are the loudest signal a developer ever produces about their own credential mistakes. If you ever wrote remove leaked api key, revoke aws, or fix exposed token in a public commit, someone has already grepped you. The window between push and exploit is not hours, it is minutes. Rotating the key is mandatory and pretending the original push never happened is not a strategy.
Pre-commit secret scanning is the only intervention that actually wins this race. Anything that runs after git push is too late. Here is the same problem from the other side: a TruffleHog pre-commit hook blocking a fake AWS key in real time.

Ten lines of YAML, adds maybe a second to your commit time. It is the cheapest insurance in security tooling.
# .pre-commit-config.yaml
repos:
- repo: https://github.com/trufflesecurity/trufflehog
rev: v3.82.0
hooks:
- id: trufflehog
args: ['git', 'file://.', '--since-commit', 'HEAD', '--only-verified', '--fail']
And about how to use language models in a security pipeline: use them to bootstrap, not to operate. They are extremely good at noticing patterns in unstructured text and extremely bad at being your hot path at scale. Mine your model’s outputs for the underlying rule, write the rule down as code, and put the model back on the bench for the next round of pattern discovery.
If your team uses AI to write production code, assume the next commit will contain a credential and design for that. Pre-commit hooks. Short-lived tokens. A git history rewrite plan that you have actually rehearsed. The Microsoft and Google examples above were caught and rotated because someone external found them and reported them. Three months after disclosure I re-checked the affected accounts: rotation held above 95%, but fewer than one in five repositories had installed a pre-commit hook to stop the next one. The next leak is probably already in someone’s training data.
Related content
- What actually happens when you leak credentials on GitHub (Mackenzie Jackson)
- GH Archive
- TruffleHog
- TruffleHog pre-commit hooks docs
- Wiz Secure Rules: AI-generated security rules for AI-generated code
References
- GH Archive event reference
- TruffleHog detector catalog
- Canary Tokens (Thinkst)
- GitHub: Removing sensitive data from a repository
- howtorotate.com rotation tutorials
- CWE-798: Use of Hard-coded Credentials
- CWE-540: Inclusion of Sensitive Information in Source Code